The previous post was spent outlining the basics of text mining and exploring some possible avenues for analysis. I learnt a lot in the process and hopefully was able to convey at least some of the potential for digital exploitation of historic texts. In this post I want to label each offence with as precise a date as possible and also assigning some basic categories to the allegations. I can do the first by extracting days, month, or years from the text to new columns and the pairing these with the original text. Essentially this approach breaks the text of the trials into smaller observations which are then filtered according to particular criteria, in this case, dates. This list is then appended to the original text which will give each allegation a modern, machine readable date.
To categorise the offences I take a similar approach. To do this I will use some of the words I extracted in the previous post. For example one of the words that I found was ‘feloniously’. This word only ever refers to property or personal violence. As I am not, at this stage, concerned with differentiating between the two I can assign this word a high value for a ‘violence’ category. This process can be repeated, with some more nuance, to assign more precise categories. These words and their values can be cross checked with the original text to give each allegation a particular value.
Dating the roll
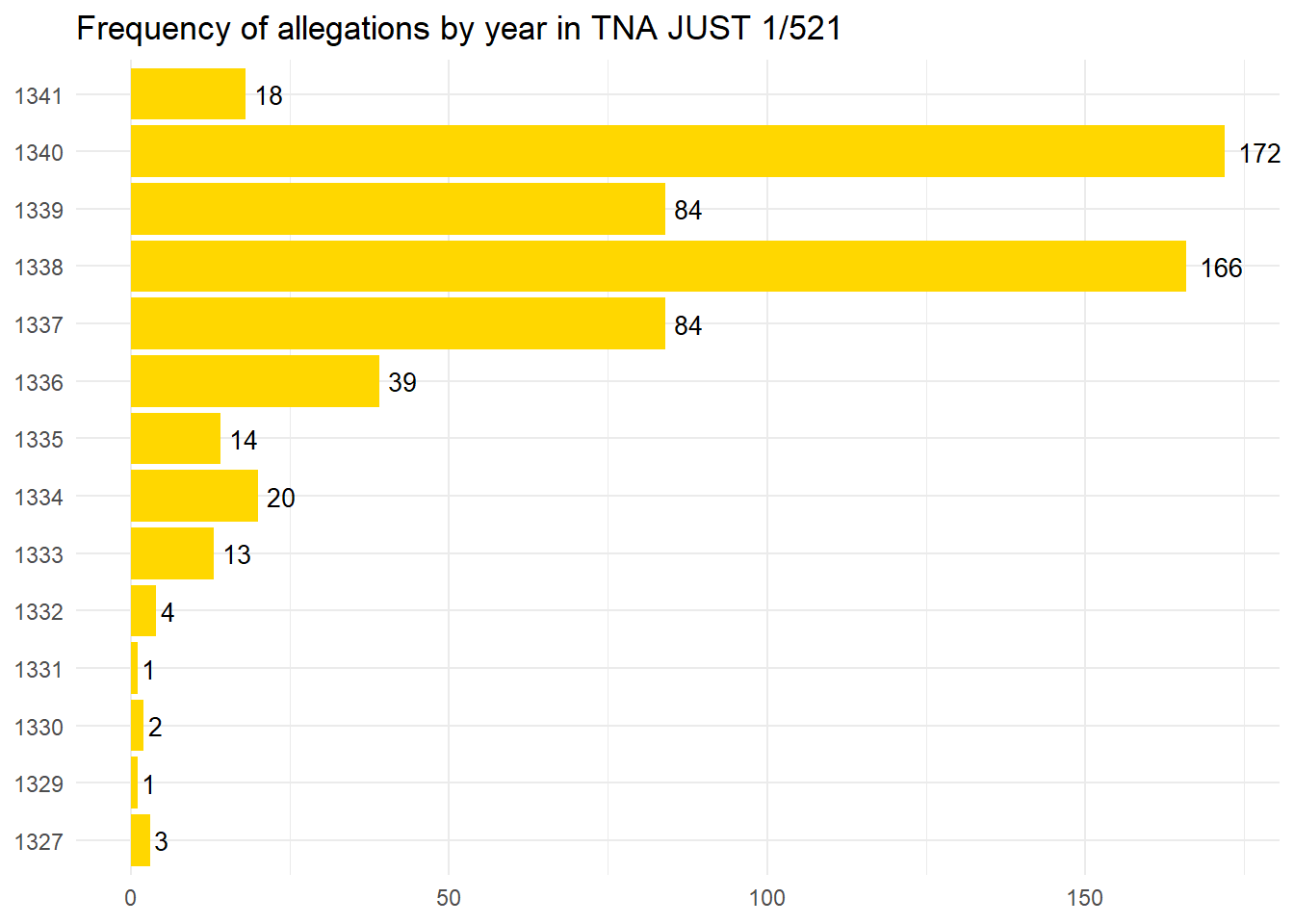
Initially, assigning years to each allegation is a fairly straightforward process. In some instances McLane, the editor of the roll, used calendar years ‘1327’ etc. I quickly realised however that, on occasion, he also used regnal years, for example, ‘Edward 3’ to refer to the third year of the king Edward. This is typically how medieval documents would date a particular year. Below is the plot of allegations which contain a calendar year. As before if you are new to R or coding please don’t worry about understanding the code. I have supplied it so you can see my workings and in case it is of interest.
#In this command I create a filter which extracts allegations with at least a year mentioned. This creates a table of allegations which include a year.yearsCount <- Lincolnshire_Tokens %>%filter(word %in%c("1327", "1328", "1329", "1330", "1331", "1332", "1333", "1334", "1335", "1336", "1337", "1338", "1339", "1340", "1341")) %>%count(word, sort =TRUE)# This plot shows which years are most commonly mentioned in the allegationsplot1Year <- yearsCount %>%ggplot(aes(word, n)) +geom_col(fill="#ffd700", position ="dodge") +geom_text(aes(label=n), hjust=-0.3, size=3.5) +ggtitle("Frequency of allegations by year in TNA JUST 1/521")+ylab(NULL) +xlab(NULL) +coord_flip() +theme_minimal()plot1Year
Converting Regnal Years
The trial was commissioned in December 1340 so it is unsurprising that the majority of offences are said to have happened in the preceding year. The spike in 1338 is likely due to the wool levy of 1338. Later, in order to test this I will tag each allegation according to categories. The plot is a crude measure but does demonstrate the recency bias of the allegations heard by the justices. Complainants or juries seem to have been more likely to bring offences which occurred close to the trial to the justices. It might be that other courts, local or royal, heard earlier offences or perhaps complainants were less willing to bring forward old allegations. As stated earlier, this data only includes those allegations which have exact dates (year, month, and day). Most documents produced by medieval English courts dated events according to their proximity to saints feast days. For example a common date might be ‘the nearest Thursday after Michaelmas in the fourth year of Edward III’. Quite a bit of work is required to update these to modern dates as some feasts are movable (they occur at different times from year-to-year). In this corpus many charges simply include a regnal year. This is problematic for updating to calendar years as a regnal year runs from the date of the monarch’s ascension yearly until the monarch dies, is deposed, or abdicates. Richard II’s regnal year, for example, runs from the 22nd of June to the 21st of June. Even worse King John’s regnal year began on on a movable feast so the start date of John’s regnal years change annually. An event which is relayed as just ‘Richard 1’ could have taken place anywhere from the 22nd of June 1377 to 21st of June 1378. In these instances it would be better to retain the regnal dating rather than updating to a calendar year. Luckily Edward III was crowned on the 25th of January which simplifies matters. A regnal year of ‘12 Edward III’ will have taken place between January 25th 1338 and January 24th 1339. For the purposes of the analysis events on a year-by-year basis I am comfortable with the 25 day margin of error. Now I can get on with extracting regnal dates and then converting them to calendar years.1
Firstly, I break the text into two-word pairings (bi-grams) using unnest_tokens(). Then I break these two-word pairings into separate columns which I can filter() for those pairings which have a digit followed by ‘Edward’. Afterwards I reunite the columns using unite() for the rest of the analysis. Then I can convert those regnal years into modern calendar years.
#First I have to break the corpus into bigrams (two word pairings)lincs_bigrams <- LincolnshireEvents %>%unnest_tokens(bigram, QUOTE_TRANSCRIPTION, token ="ngrams", n =2)#In order to extract the regnal years however I need to split this text into two columns which I can filterbigrams_separated <- lincs_bigrams %>%separate(bigram, c("word1", "word2"), sep =" ")#Filter for the regnal yearsregYears <- bigrams_separated %>%filter(word1 %in%c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "12", "13", "14", "15")) %>%filter(word2 %in%"edward") #Unite the columns for analysisregYears_united <- regYears %>%unite(bigram, word1, word2, sep =" ")
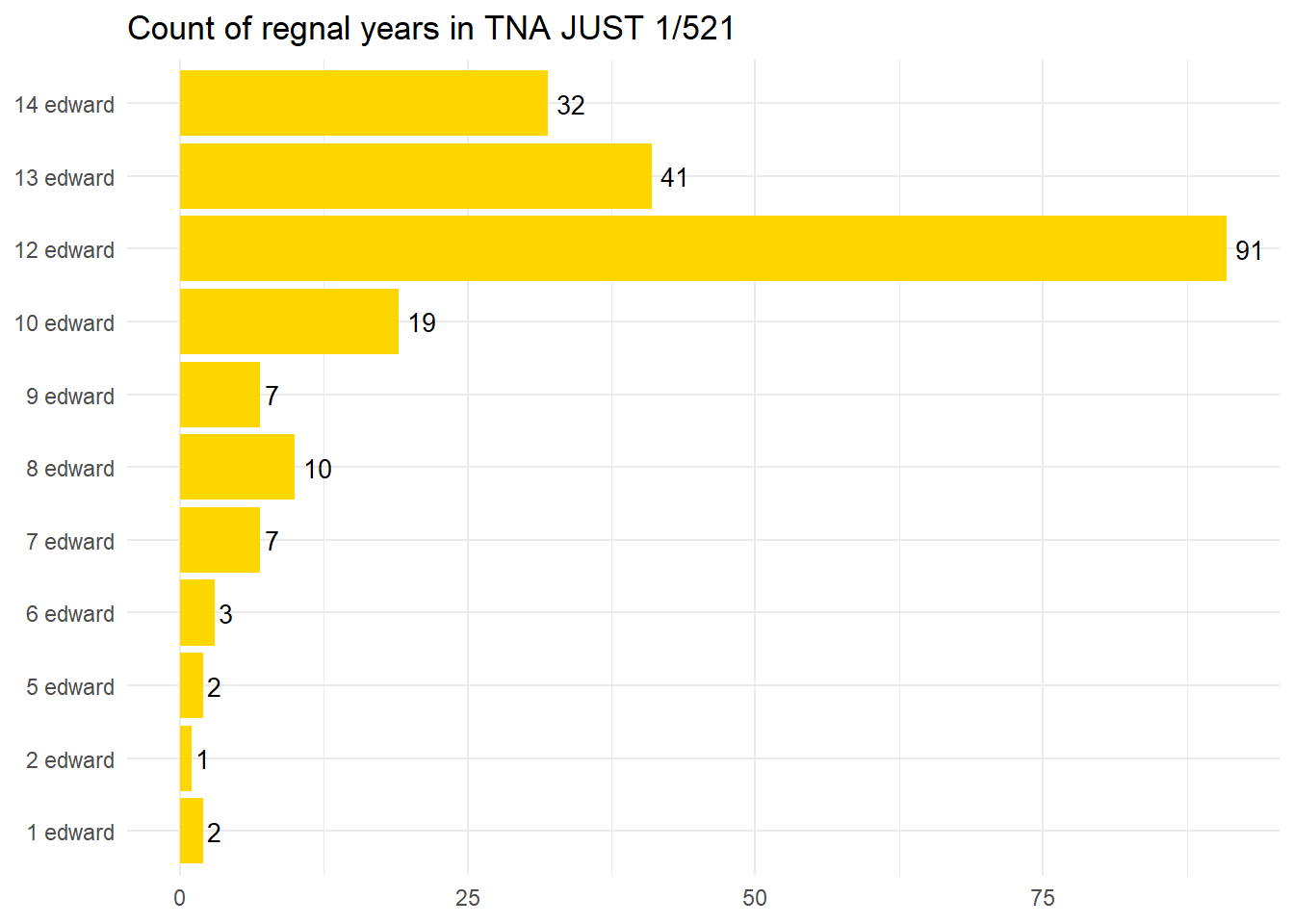
Now I have a list of all the regnal years and in the plot below we can see the pattern is similar to the earlier plot but with one clear change. As before, when the data included only offences with a precise date (day, month, year), the majority of offences were said to have taken place in the three years before the trial. However this data, which is only dated to a twelve month period, the preponderance of allegations are in 1338. This discrepancy highlights that when allegations which relate to events more than two years prior the juries or complainants were unable to specify accurate dates. This is unsurprising. More surprising is that complainants or juries were able to give such precise dates for events over a decade prior. It seems likely that many of these are the result of local records, exchequer records, or tallies which gave exact dates. These would likely be the product of tax offences of some other similar activities which relied on record keeping. It’s likely that some of the precise dates were easy to remember. A crime which took place on a feast day, for example, would be relatively easy for a victim to remember even years later. Perhaps, at times, precise dates were also given as approximations.
#Count of regnal yearsregYears_count <- regYears_united %>%count(bigram, sort =TRUE)#Plot of regnal years sorted chronologicallyplotRegnal <- regYears_count %>%mutate(bigram =fct_relevel(bigram, '1 edward', '2 edward', '3 edward', '4 edward', '5 edward', '6 edward', '7 edward', '8 edward', '9 edward', '10 edward', '11 edward', '12 edward', '13 edward', '14 edward')) %>%ggplot(aes(bigram, n)) +geom_col(fill="#ffd700", position ="dodge") +geom_text(aes(label=n), hjust=-0.3, size=3.5) +ggtitle("Count of regnal years in TNA JUST 1/521")+ylab(NULL) +xlab(NULL) +coord_flip() +theme_minimal()plotRegnal
Next I appended the corpus to tag each allegation with a regnal year and converted them to calendar years.
#Convert Regnal Yearls to calendar yearregYears_converted <- regYears_united %>%mutate(bigram =case_when(bigram =="1 edward"~"1327", bigram =="2 edward"~"1328", bigram =="3 edward"~"1329", bigram =="4 edward"~"1330", bigram =="5 edward"~"1331", bigram =="6 edward"~"1332", bigram =="7 edward"~"1333", bigram =="8 edward"~"1334", bigram =="9 edward"~"1335", bigram =="10 edward"~"1336", bigram =="11 edward"~"1337", bigram =="12 edward"~"1338", bigram =="13 edward"~"1339", bigram =="14 edward"~"1340"))#Rename column to match for mergingregYears_converted <- regYears_converted %>%rename(year = bigram)#Create new column to tag as Regnal dateregYears_converted <- regYears_converted %>%mutate(regnalYear =!is.na(year))#Tags each entry with a regnal yearregnalTagged <-full_join(regYears_converted, LincolnshireEvents)
Joining the years
Now I have converted the regnal dates I can join this table to the earlier table which tagged each allegation according to the calendar year mentioned. The following command ‘full_join()’ merges two tables. If the column name match then they are merged and when they don’t then the surplus columns are added. So before I carry out the merge I need to rename the columns I wish to merge or I will have two columns when I only want one. I do this with the command regnalTagged <- regnalTagged %>% rename(word = bigram). This takes the column ‘bi-gram’ and renames it ‘word’. Now the two columns, which have a list of years alongside the id of allegations in Lincolnshire will merge.
#Merge of the converted regnal years and the calendar yearsyearsCombined<-full_join(years, regnalTagged)
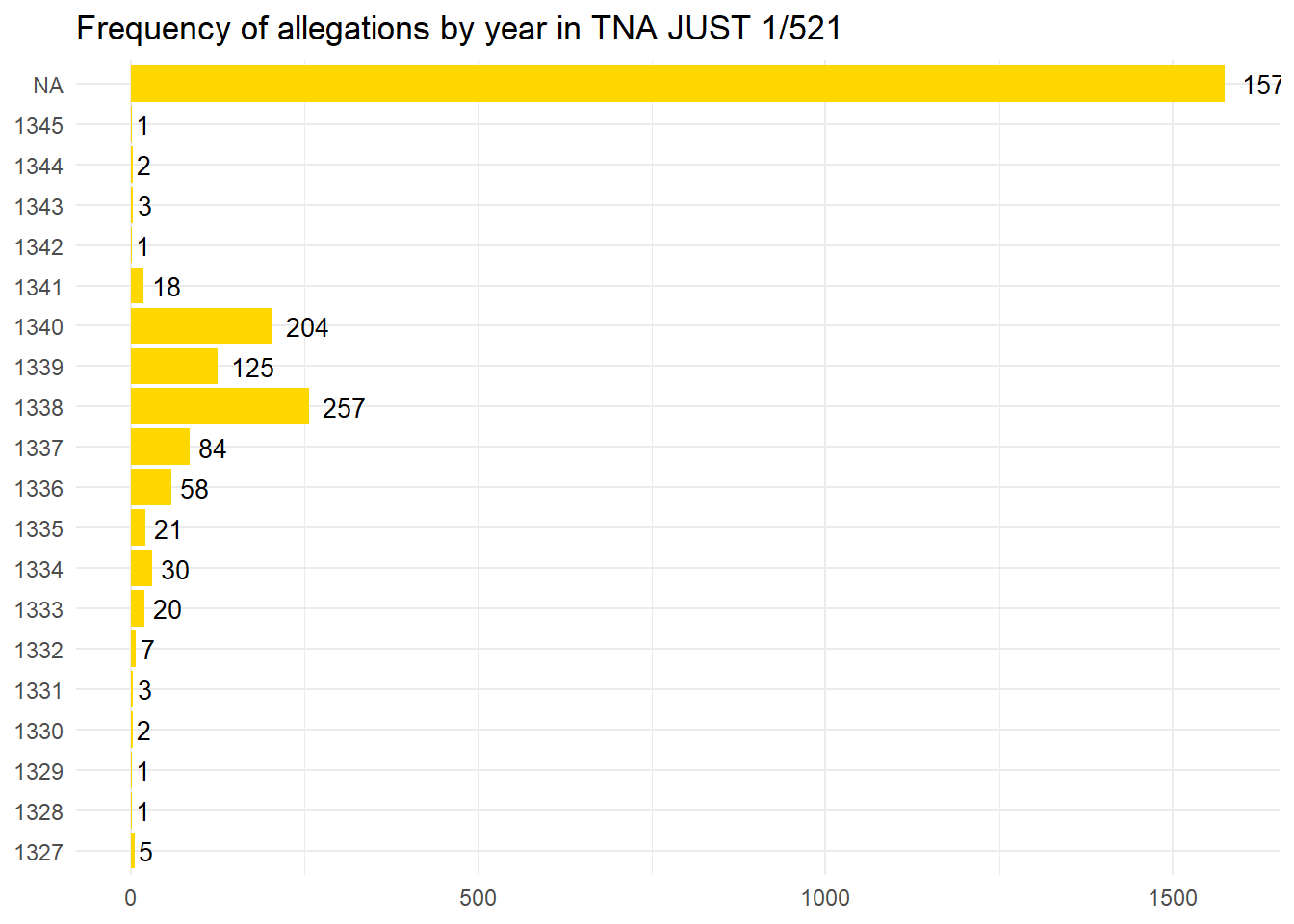
This is a plot of the count of the merged table, which includes both regnal and calendar years. It shows the preponderance of charges in 1338 which probably relates to the wool levy. This was used to fund the early phases of the war with the French crown which later became known as The Hundred Years War. The small number of mentions in 1341 relate to the business of the court or offences that
# If 'n' is supposed to be a count of each year, ensure it's created firstyearsCount <- yearsCombined %>%count(year) %>%rename(n = n) # This renames the count column to 'n' if it's not already named 'n'yearsCount %>%ggplot(aes(year, n)) +geom_col(fill="#ffd700", position ="dodge") +geom_text(aes(label=n), hjust=-0.3, size=3.5) +ggtitle("Frequency of allegations by year in TNA JUST 1/521")+ylab(NULL) +xlab(NULL) +coord_flip() +theme_minimal()
Adding Day and Month
Finally I want to add the month and date to the data. To do this is essentially a repeat of some of the earlier processes with some differences and elaborations. I include the full code here to show the process from start to finish but it is essentially a slight variation of what I have already outlined. Step one is turning the text into three-word observations which will capture instances of day-month-year, this is then split into three columns and filtered to capture months.
#Create Trigrams lincs_trigrams <- LincolnshireEvents %>%unnest_tokens(trigram, QUOTE_TRANSCRIPTION, token ="ngrams", n =3)#Count of most common trigramstrigrams_count <- lincs_trigrams %>%count(trigram, sort =TRUE)#Split into three columnstrigrams_separated <- lincs_trigrams %>%separate(trigram, c("word1", "word2", "word3"), sep =" ")#Filter for the monthsfullDates <- trigrams_separated %>%filter(word2 %in%c("january", "february", "march", "april", "may", "june", "july", "august", "september", "october", "november", "december", "jan", "feb", "mar", "apr", "may", "jun", "jul", "aug", "sep", "oct", "nov", "dec", "sept"))
This essentially has created a list which includes all the instances of a month being mentioned in either the long or short format. The following looks quite complicated but is rather simple. I have tried to explain the process in the comments accompanying the code. Simply put the following cleans the data by weeding out errors in the original publication, or in the OCR, or in digitising process and then converts the months from text to digits.
#This fixes errors which result from the formating of the original text that had no space between the comma and the digits which refer to a date eg. '1,26' rather than '1, 26'. So when it was seperated into trigrams it detected it as a single word rather than two words.fullDates$word1[fullDates$word1 =="1,26" ] <-26fullDates$word1[fullDates$word1 =="186,25" ] <-25fullDates$word1[fullDates$word1 =="536,4" ] <-04#These result from the OCR reading 27 as t1 or interpreting the superscript '1' and '2' from footnotes as normal digits.fullDates$word1[fullDates$word1 =="t1" ] <-27fullDates$word3[fullDates$word3 =="13401" ] <-1340fullDates$word3[fullDates$word3 =="13402" ] <-1340#In these allegations there were multiple dates and these instances were referring back to a prior date. The year was not included as it was inferred from the earlier instance. fullDates$word3[fullDates$word3 =="and" ] <-1338fullDates$word3[fullDates$word3 =="gilbert" ] <-1338fullDates$word3[fullDates$word3 =="to" ] <-1339fullDates$word3[fullDates$word3 =="at" ] <-1330fullDates$word3[fullDates$word3 =="paid" ] <-1339#The following two commands remove rows which were incorrectly added as they interpreted personal names as months ('mar' for marshal or the surname 'la march')fullDates <- fullDates %>%filter(word1 !="la")fullDates <- fullDates %>%filter(word3 !="shal")#This looks complicated but it takes each month which converts it to a digit for calculationsfullDates <- fullDates %>%mutate(word2 =case_when(word2 =="january"~"01", word2 =="february"~"02", word2 =="march"~"03", word2 =="april"~"04", word2 =="may"~"05", word2 =="june"~"06", word2 =="july"~"07", word2 =="august"~"08", word2 =="september"~"09", word2 =="october"~"10", word2 =="november"~"11", word2 =="december"~"12", word2 =="jan"~"01", word2 =="feb"~"02", word2 =="mar"~"03", word2 =="apr"~"04", word2 =="may"~"05", word2 =="jun"~"06", word2 =="jul"~"07", word2 =="aug"~"08", word2 =="sep"~"09", word2 =="oct"~"10", word2 =="nov"~"11", word2 =="dec"~"12", word2 =="sept"~"09"))
Now the cleaning process is finished I can convert the days into a format which R recognises as a date and then join the tables of exact dates to the text which contains the allegations. This is carried out by merging the data into a single column in the second line of code with mutate(date = make_date(year, month, day)). This takes the columns ‘year, ’month’, ‘day’ and combines them into a single column which is then converted into a date format with the make_date() command and places it into a new column called ‘date’.
#Rename columns to year, month, dayfullDates <- fullDates %>%rename(day = word1, month = word2, year = word3)#Create new column with date in correct formatfullDates <- fullDates %>%mutate(date =make_date(year, month, day))#Merge fullDates table with the original textfullDated <-full_join(LincolnshireEvents, fullDates)#Finally I merge the converted regnal years, the calendar years, and allegations with precise dating to the original data which includes all allegationsyearsDated <-full_join(yearsCombined, fullDated)lincsEventsDated <-full_join(yearsDated, LincolnshireEvents)
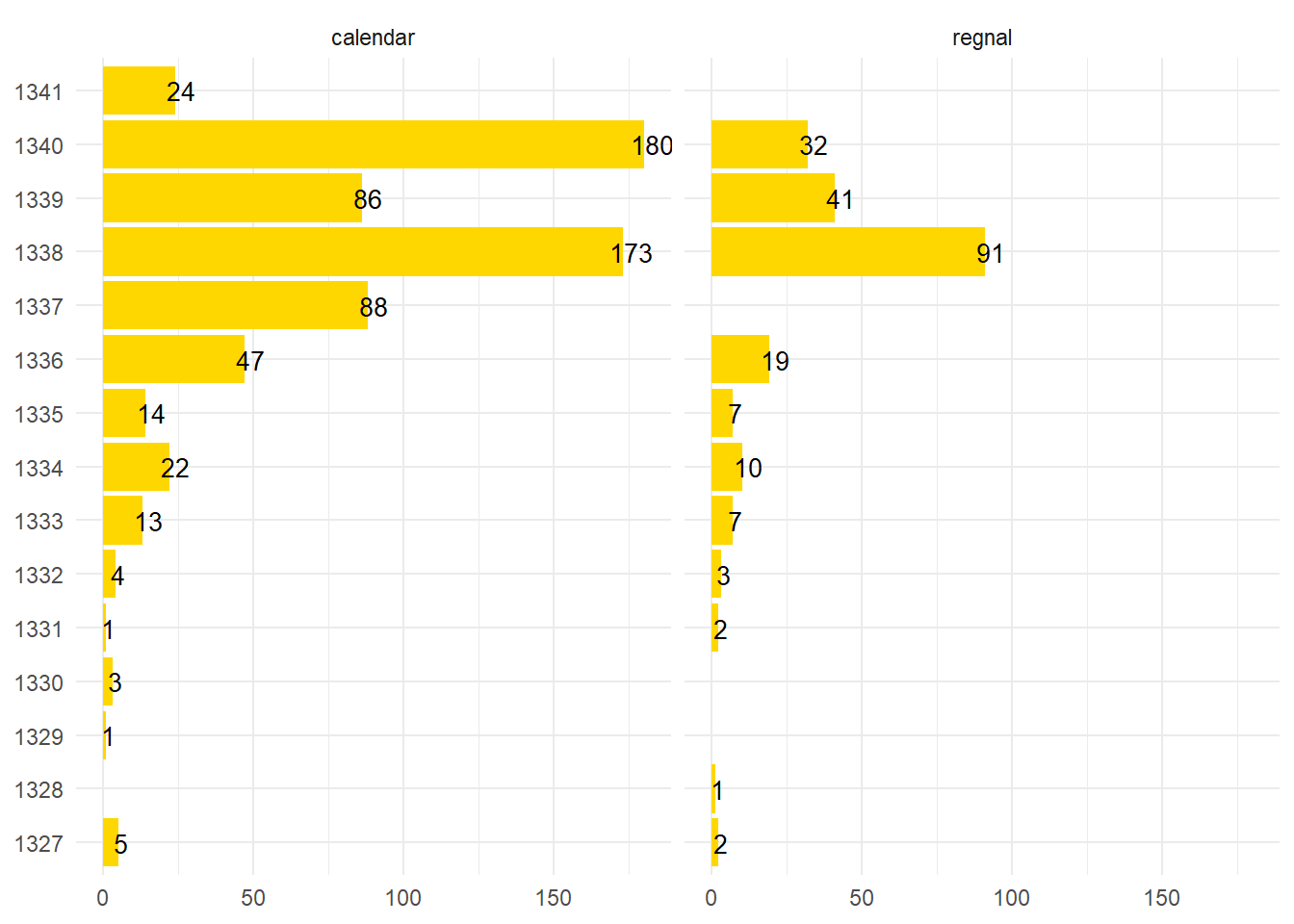
Now I have all allegations from the data set tagged which include some kind of temporal information tagged with a year at minimum and in roughly 600 instances a year, month, and day. Now we can we plot the two graphs side-by-side which shows that those allegations that were only dated by a calendar year tended to be in 1338. Why this occurs will have to wait for a more detailed analysis of the dating.
#Plot of regnal years and calendar years side-by-sidelincsEventsDated %>%filter(!is.na(regnalYear)) %>%filter(year %in%c("1327", "1328", "1329", "1330", "1331", "1332", "1333", "1334", "1335", "1336", "1337", "1338", "1339", "1340", "1341")) %>%count(year, regnalYear, sort=TRUE) %>%ggplot(aes(year, n)) +geom_col(fill="#ffd700", position ="dodge") +geom_text(aes(label=n), hjust=0.3, size=3.5) +ylab(NULL) +xlab(NULL) +facet_wrap(. ~regnalYear) +coord_flip() +theme_minimal()
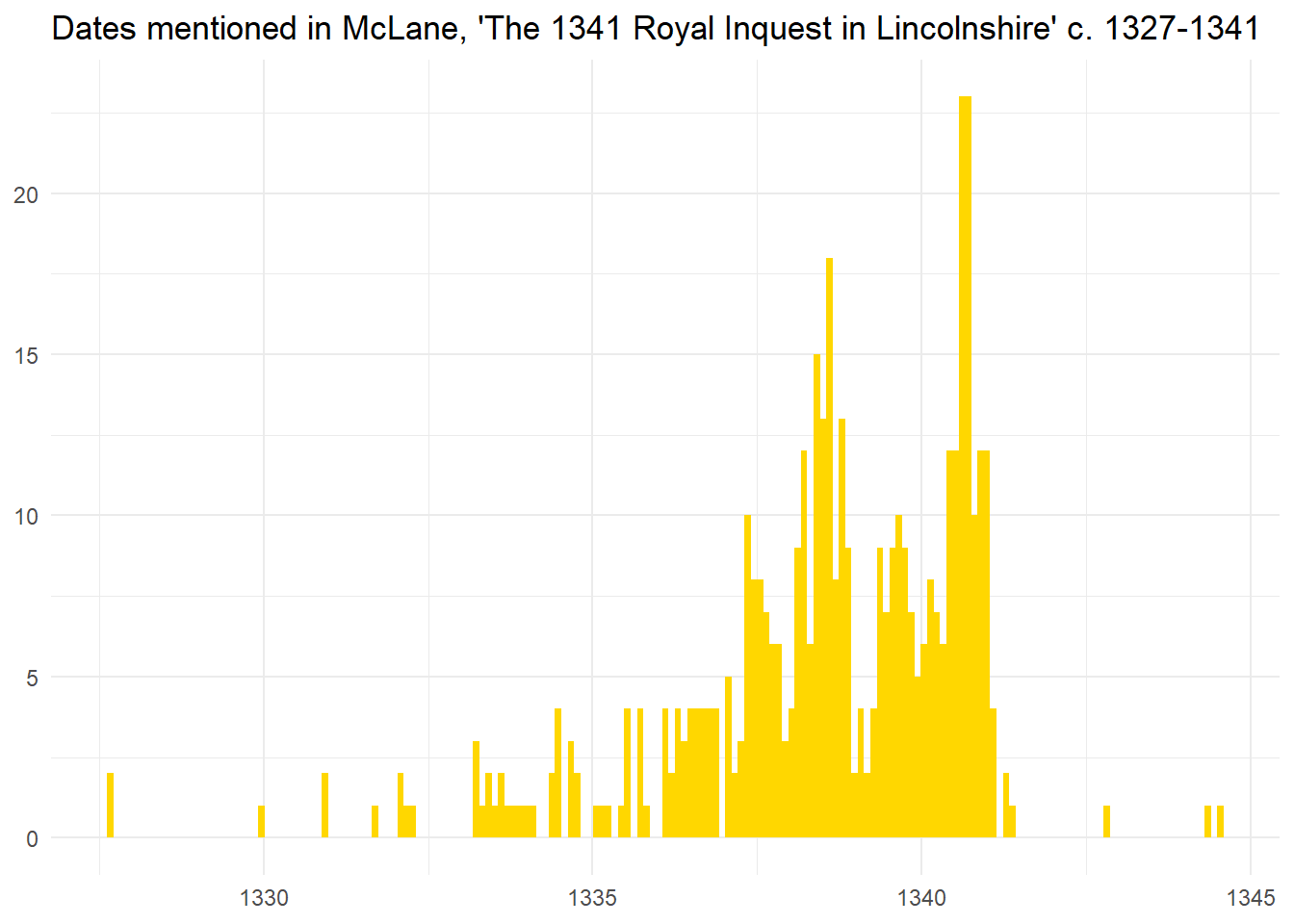
We can also plot all allegations which are dated to day, month, and year across the entirety of the court records.
#Convert Year into a factorlincsEventsDated$year <-factor(lincsEventsDated$year)#PlotlincsEventsDated %>%count(date, year, sort=TRUE) %>%ggplot(aes(date)) +geom_histogram(fill="#ffd700", binwidth =35) +ggtitle("Dates mentioned in McLane, 'The 1341 Royal Inquest in Lincolnshire' c. 1327-1341")+ylab(NULL) +xlab(NULL) +theme_minimal()
#I did have each year labeled on the x axis but I broke it somehow. If you know how to fix it please tell me!
In this post I have outlined how to work with dates in several formats and add new columns to the data which can act as a tag and reveal trends. I want to point out a few things about the approach I have taken though. One problem is that each allegation might include multiple dates. In those instances I will have created duplicate entries. This isn’t a huge problem as I am interested in the focus of the court. When editing the volume McLane followed the construction of the records by the court clerks. Some individual allegations in fact contain many offences which may have occurred at different times. If I attempted to just assign a single date to each allegation I would have to exclude a lot of information. It does mean however that the data I have shown here only demonstrates the number of times that a particular date is mentioned rather than dating each allegation specifically. I learnt quite a lot and I am sure if I began again I would make some changes to the process I have outlined. I think, at times, I took several steps when only one or two were necessary. The next post will have more analysis of the work carried out here and less coding!
Footnotes
If you are interested in reading further the University of Nottingham has a good guide on regnal years.↩︎